---
title: "Issue #2 - AI模型性能投票分析"
subtitle: "排序数据的采集、处理与多维度可视化"
format:
html:
toc: true
toc-depth: 3
code-fold: show
code-summary: "显示/隐藏代码"
code-tools: true
editor: visual
execute:
warning: false
message: false
---
## 案例概述
本案例展示如何**分析排序数据(Ranked Data)**,通过对学生投票的不同 AI 模型排名进行多维度分析,理解排序数据的特性和分析方法。
### 学习目标
完成本案例学习后,您将能够:
1. **理解排序数据特性**:掌握排序数据与普通分类数据的区别
2. **数据格式转换**:使用 `tidyr` 进行长宽格式转换
3. **多维度统计分析**:从票数、排名、分布等角度分析数据
4. **高级可视化**:创建热力图、箱线图等复杂图形
5. **结果解读**:从数据中提取有意义的洞察
### 什么是排序数据?
排序数据(Ranked Data)是指受访者对一组选项进行排序后产生的数据。与简单的投票(选择最喜欢的)不同,排序数据包含了更丰富的信息:
| 数据类型 | 示例 | 信息量 |
|----------|------|--------|
| **单一选择** | 最喜欢的模型:GPT-4o | 低:只知道第一名 |
| **多选** | 喜欢的模型:GPT-4o, Claude | 中:知道喜欢哪些 |
| **排序** | 1.GPT-4o 2.Claude 3.Gemini | 高:知道相对偏好 |
**排序数据的优势:**
- 捕获选项间的相对偏好强度
- 允许进行更细致的统计分析
- 减少"策略性投票"(只选第一名)的影响
### 数据结构
| 字段 | 类型 | 说明 | 示例 |
|------|------|------|------|
| `user` | character | 投票者 GitHub 用户名 | "alice" |
| `rank` | integer | 排名(1-5) | 1 |
| `model` | character | AI 模型名称 | "GPT-4o" |
---
## 数据获取与解析
### 数据来源
数据来自 [GitHub Issue #2](https://github.com/D2RS-2026spring/members/issues/2),学生以评论形式提交对 AI 模型的排序投票:
```markdown
1. GPT-4o
2. Claude Sonnet 3.5
3. Gemini Pro
4. Kimi
5. DeepSeek
```
### 数据获取
```{r}
#| label: setup
#| include: false
library(httr)
library(jsonlite)
library(dplyr)
library(stringr)
library(ggplot2)
library(tidyr)
library(showtext)
# 配置中文字体
if (file.exists("/System/Library/Fonts/wqy-microhei.ttc")) {
font_add("WenQuanYi", "/System/Library/Fonts/wqy-microhei.ttc")
} else if (file.exists("/usr/share/fonts/truetype/wqy/wqy-microhei.ttc")) {
font_add("WenQuanYi", "/usr/share/fonts/truetype/wqy/wqy-microhei.ttc")
}
showtext_auto()
```
```{r}
#| label: data-acquisition
# 检查并使用缓存数据
cache_file <- "issue2_comments.json"
if (!file.exists(cache_file)) {
system("gh api repos/D2RS-2026spring/members/issues/2/comments --paginate > issue2_comments.json")
message("已从 GitHub API 获取数据")
} else {
message("使用本地缓存数据")
}
# 读取数据
all_comments <- fromJSON(cache_file, simplifyVector = TRUE)
cat("获取到", nrow(all_comments), "条投票评论\n")
```
### 模型名称标准化
在解析之前,我们需要定义模型名称的映射规则,以处理同一模型的不同写法:
```{r}
#| label: model-mapping
# 定义模型名称映射表
# 键:可能的输入形式(小写,用于匹配)
# 值:标准化后的显示名称
model_mapping <- c(
# OpenAI 模型
"gpt-5" = "GPT-5",
"gpt-4o" = "GPT-4o",
"gpt-4" = "GPT-4",
"gpt-3.5" = "GPT-3.5",
"gpt-3.5-turbo" = "GPT-3.5",
# Anthropic 模型
"claude-opus" = "Claude Opus",
"claude-sonnet" = "Claude Sonnet",
"claude-haiku" = "Claude Haiku",
"claude-3" = "Claude 3",
"claude-3.5" = "Claude 3.5",
"claude-3.5-sonnet" = "Claude 3.5 Sonnet",
# Google 模型
"gemini" = "Gemini",
"gemini-pro" = "Gemini Pro",
"gemini-ultra" = "Gemini Ultra",
# 中国厂商模型
"deepseek" = "DeepSeek",
"deepseek-r1" = "DeepSeek-R1",
"kimi" = "Kimi",
"kimi-k1.5" = "Kimi K1.5",
"qwen" = "Qwen",
"qwen-max" = "Qwen Max",
"glm" = "GLM",
"chatglm" = "ChatGLM",
"minimax" = "MiniMax",
# 其他
"grok" = "Grok",
"grok-2" = "Grok 2"
)
cat("定义了", length(model_mapping), "个模型名称映射\n")
```
### 排序数据解析
解析排序数据的关键是识别以数字开头的行,并提取其中的模型名称:
```{r}
#| label: data-parsing
#' 从文本中提取模型排名
#'
#' @param body 评论正文
#' @return 数据框,包含 rank 和 model 两列
extract_models <- function(body) {
# 按行分割
lines <- str_split(body, "\n")[[1]]
# 筛选以数字开头的行(排名行)
# 匹配模式:数字 + [..、] + 任意内容
rank_lines <- lines[str_detect(lines, "^\\d+[..、]")]
if (length(rank_lines) == 0) {
return(NULL)
}
models <- c()
ranks <- c()
for (i in seq_along(rank_lines)) {
line <- rank_lines[i]
# 提取排名数字
rank <- as.numeric(str_extract(line, "^\\d+"))
# 尝试匹配模型名称
matched_model <- NA_character_
line_lower <- tolower(line)
for (pattern in names(model_mapping)) {
if (str_detect(line_lower, pattern)) {
matched_model <- model_mapping[pattern]
break
}
}
if (!is.na(matched_model)) {
models <- c(models, matched_model)
ranks <- c(ranks, rank)
}
}
if (length(models) == 0) {
return(NULL)
}
data.frame(
rank = ranks,
model = models,
stringsAsFactors = FALSE
)
}
# 测试解析函数
test_vote <- "1. gpt-4o\n2. claude-sonnet\n3. gemini\n4. kimi\n5. deepseek"
cat("测试文本:\n", test_vote, "\n\n解析结果:\n")
print(extract_models(test_vote))
```
### 批量解析所有投票
```{r}
#| label: batch-parsing
# 遍历所有评论并解析
comments_list <- split(all_comments, seq(nrow(all_comments)))
vote_data_list <- lapply(seq_along(comments_list), function(i) {
comment <- comments_list[[i]]
parsed <- extract_models(comment$body)
if (!is.null(parsed) && nrow(parsed) > 0) {
parsed$user <- comment$user$login
parsed$comment_id <- comment$id
parsed$created_at <- comment$created_at
return(parsed)
}
return(NULL)
})
# 合并所有解析结果
vote_data <- bind_rows(vote_data_list)
cat("解析结果:\n")
cat("- 有效投票人数:", length(unique(vote_data$user)), "\n")
cat("- 排名记录总数:", nrow(vote_data), "\n")
cat("- 识别到的模型数:", length(unique(vote_data$model)), "\n")
```
---
## 排序数据的统计分析方法
### 排序数据的特性
排序数据与普通连续数据不同,具有以下特点:
1. **序数性**:排名只表示顺序,不表示差距(第1名和第2名的差距不一定等于第2名和第3名的差距)
2. **有界性**:排名在一定范围内(如1-5)
3. **互斥性**:同一投票者的排名中,每个排名位置只有一个选项
### 分析维度
对于排序数据,我们可以从多个维度进行分析:
| 维度 | 指标 | 说明 |
|------|------|------|
| **频次分析** | 总票数 | 各模型被提及的总次数 |
| **位置分析** | 第一名次数 | 各模型被选为第1名的频次 |
| **集中趋势** | 平均排名 | 各模型的平均排名位置(越小越好) |
| **离散程度** | 排名分布 | 各模型在不同排名位置的分布 |
| **一致性** | 标准差 | 排名的一致程度 |
---
## 数据统计与汇总
### 1. 基础频次统计
```{r}
#| label: frequency-stats
# 计算各模型的总票数
total_votes <- vote_data %>%
count(model, sort = TRUE, name = "total_votes")
# 计算各模型获得第一名的次数
first_place <- vote_data %>%
filter(rank == 1) %>%
count(model, sort = TRUE, name = "first_place_votes")
# 合并统计结果
model_stats <- total_votes %>%
left_join(first_place, by = "model") %>%
mutate(
first_place_votes = replace_na(first_place_votes, 0),
first_place_rate = round(first_place_votes / total_votes * 100, 1)
)
knitr::kable(head(model_stats, 10),
caption = "模型投票基础统计 (Top 10)",
col.names = c("模型", "总票数", "第一名次数", "第一名占比%"))
```
### 2. 平均排名计算
```{r}
#| label: average-rank
# 计算各模型的平均排名
avg_rank <- vote_data %>%
group_by(model) %>%
summarise(
avg_position = mean(rank),
median_position = median(rank),
std_dev = sd(rank),
total_votes = n(),
.groups = "drop"
) %>%
# 只统计被投票次数较多的模型(避免样本量太小)
filter(total_votes >= 3) %>%
arrange(avg_position)
knitr::kable(head(avg_rank, 10),
caption = "模型平均排名统计 (平均排名越小越好)")
```
**解读平均排名:**
- **平均排名 < 2**:普遍被认为是顶级模型
- **平均排名 2-3**:中上水平的模型
- **平均排名 > 3**:被认为相对较弱的模型
### 3. 排名分布矩阵
```{r}
#| label: rank-distribution
# 创建排名分布矩阵
rank_matrix <- vote_data %>%
filter(rank <= 5) %>%
count(model, rank) %>%
pivot_wider(
names_from = rank,
values_from = n,
values_fill = 0,
names_prefix = "Rank_"
)
# 合并统计数据
rank_matrix_full <- avg_rank %>%
select(model, avg_position) %>%
left_join(rank_matrix, by = "model") %>%
arrange(avg_position)
knitr::kable(head(rank_matrix_full, 8),
caption = "模型排名分布矩阵")
```
---
## 数据可视化
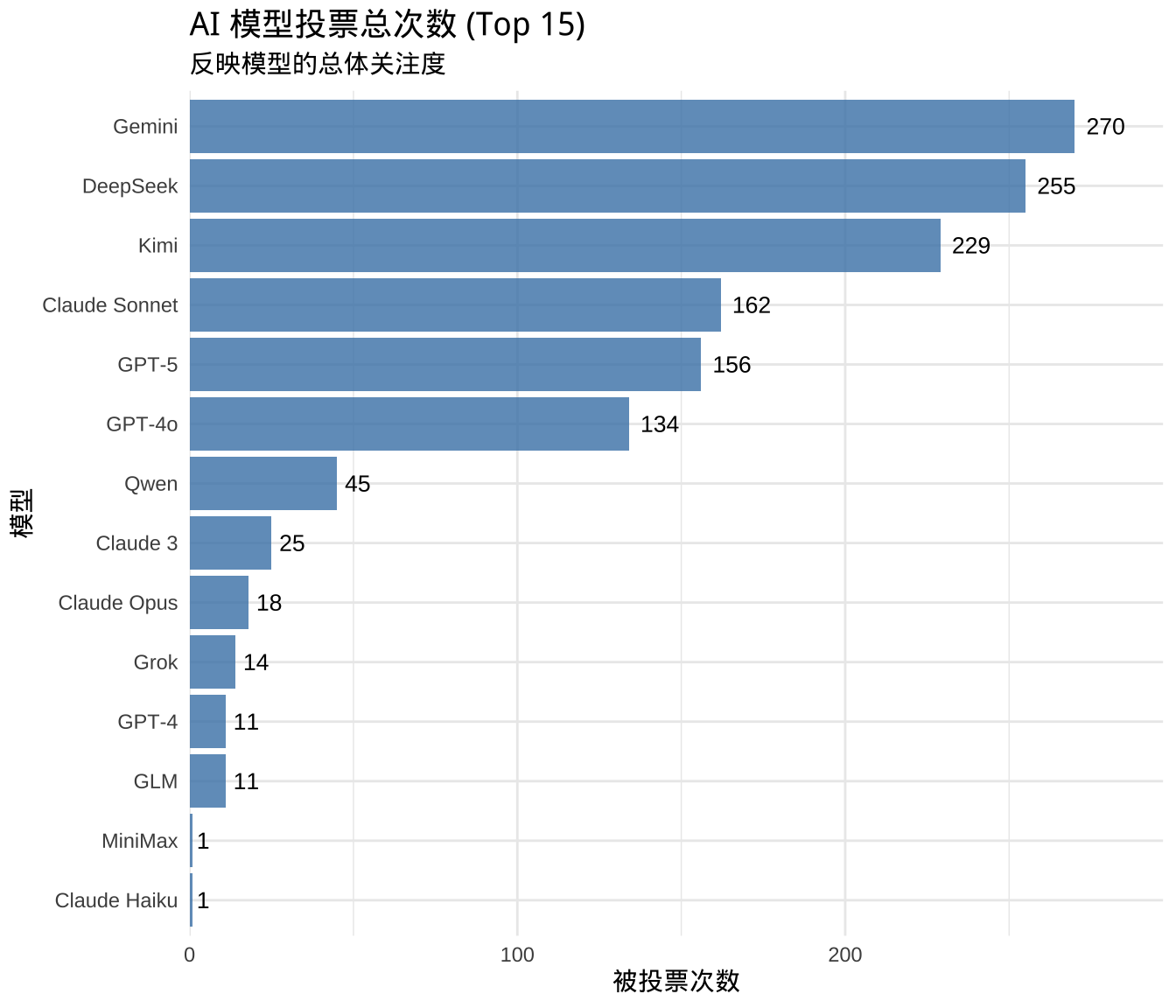
### 1. 总票数排名
```{r}
#| label: viz-total-votes
#| fig-height: 6
top_models <- head(total_votes$model, 15)
vote_data %>%
filter(model %in% top_models) %>%
count(model) %>%
ggplot(aes(x = reorder(model, n), y = n)) +
geom_bar(stat = "identity", fill = "steelblue", alpha = 0.8) +
geom_text(aes(label = n), hjust = -0.3, size = 3.5) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
labs(
title = "AI 模型投票总次数 (Top 15)",
subtitle = "反映模型的总体关注度",
x = "模型",
y = "被投票次数"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi")
)
```
### 2. 平均排名对比
```{r}
#| label: viz-avg-rank
#| fig-height: 6
avg_rank %>%
head(15) %>%
ggplot(aes(x = reorder(model, avg_position), y = avg_position)) +
geom_bar(stat = "identity", fill = "coral", alpha = 0.8) +
geom_text(aes(label = sprintf("%.2f", avg_position)),
hjust = 1.3, size = 3.5, color = "white") +
coord_flip() +
scale_y_reverse() + # 排名越小越好,所以反转Y轴
labs(
title = "AI 模型平均排名 (越低越好)",
subtitle = "综合反映模型的整体评价",
x = "模型",
y = "平均排名"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi")
)
```
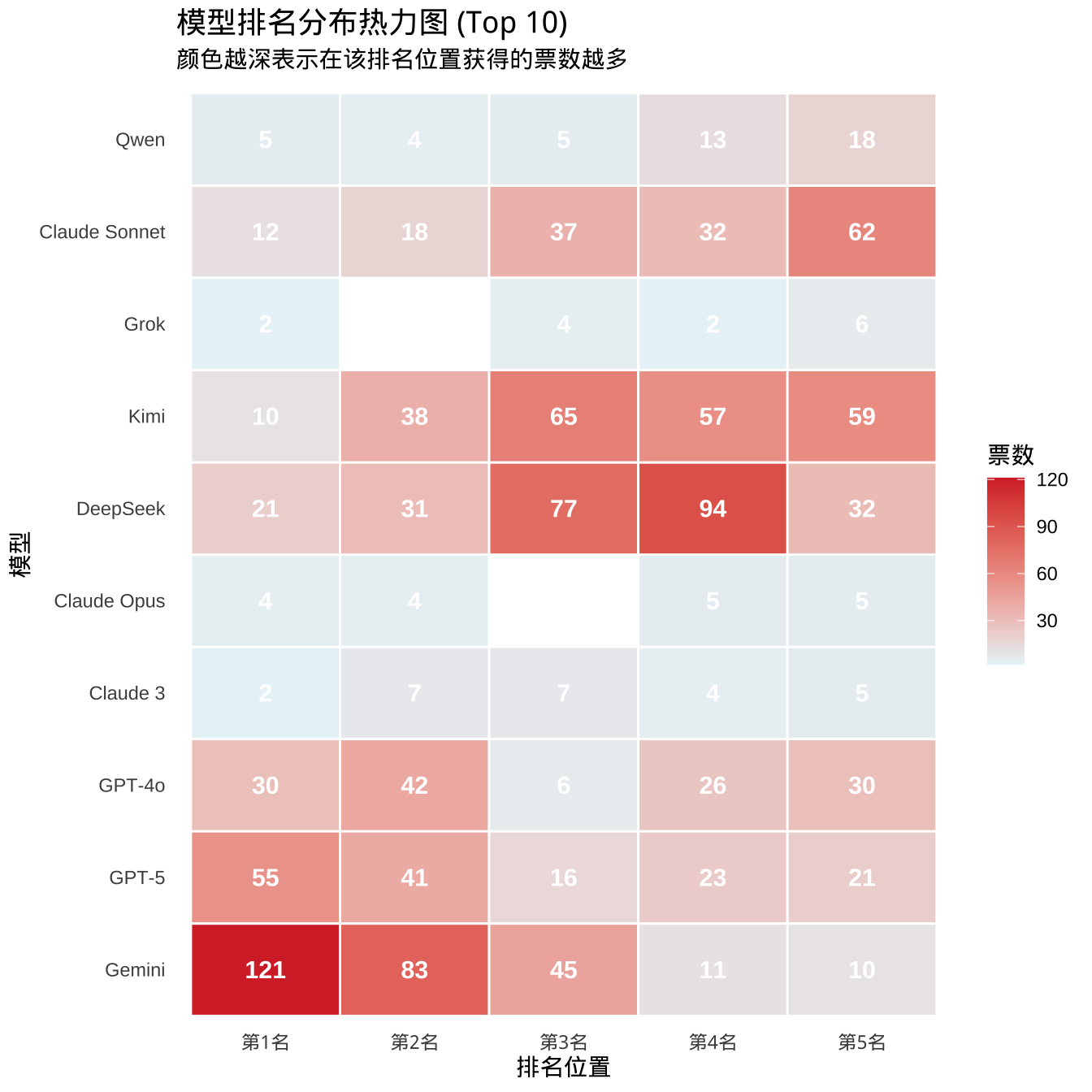
### 3. 排名分布热力图
热力图可以直观展示各模型在不同排名位置的分布情况:
```{r}
#| label: viz-heatmap
#| fig-height: 7
# 选择 Top 10 模型进行展示
top_10_models <- head(total_votes$model, 10)
# 准备热力图数据
heatmap_data <- vote_data %>%
filter(model %in% top_10_models, rank <= 5) %>%
count(model, rank) %>%
left_join(
avg_rank %>% select(model, avg_position),
by = "model"
)
# 绘制热力图
ggplot(heatmap_data,
aes(x = factor(rank, labels = paste0("第", 1:5, "名")),
y = reorder(model, avg_position),
fill = n)) +
geom_tile(color = "white", size = 0.5) +
geom_text(aes(label = n), color = "white", size = 4, fontface = "bold") +
scale_fill_gradient(
low = "#E8F4F8",
high = "#D63031",
name = "票数"
) +
labs(
title = "模型排名分布热力图 (Top 10)",
subtitle = "颜色越深表示在该排名位置获得的票数越多",
x = "排名位置",
y = "模型"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi"),
panel.grid = element_blank()
)
```
**热力图解读:**
- **横向观察**:可以看到一个模型在不同排名位置的分布
- **纵向观察**:可以比较同一排名位置上不同模型的表现
- **对角线**:如果数据理想,优秀模型应该在左侧(高排名)颜色深
### 4. 排名分布箱线图
箱线图展示排名的分布特征(中位数、四分位数、异常值):
```{r}
#| label: viz-boxplot
#| fig-height: 6
vote_data %>%
filter(model %in% top_10_models) %>%
left_join(avg_rank %>% select(model, avg_position), by = "model") %>%
ggplot(aes(x = reorder(model, avg_position), y = rank)) +
geom_boxplot(fill = "lightblue", alpha = 0.7, outlier.colour = "red") +
geom_jitter(width = 0.2, alpha = 0.3, size = 1) + # 添加原始数据点
coord_flip() +
scale_y_continuous(breaks = 1:5) +
labs(
title = "模型排名分布箱线图 (Top 10)",
subtitle = "箱体显示四分位范围,点表示异常值",
x = "模型",
y = "排名位置"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi")
)
```
**箱线图解读:**
- **箱体**:第25百分位到第75百分位(IQR)
- **箱内横线**:中位数排名
- ** whiskers**:延伸到 1.5 × IQR 范围内的最极端数据点
- **点**:超出 whiskers 范围的异常值
---
## 数据导出
将分析结果保存为 CSV 文件:
```{r}
#| label: data-export
# 创建宽格式的投票矩阵
# 注意:由于同一用户可能对同一排名有多个模型(去重后),
# 我们需要确保每个(user, rank)组合只有一个模型
vote_matrix <- vote_data %>%
# 每个用户只保留前5名
filter(rank <= 5) %>%
# 按用户和排名排序,确保稳定性
arrange(user, rank) %>%
# 去重:每个用户每个排名只保留一个模型
distinct(user, rank, .keep_all = TRUE) %>%
# 转换为宽格式
pivot_wider(
id_cols = user,
names_from = rank,
values_from = model,
names_glue = "第{rank}名"
)
# 保存为 CSV
write.csv(vote_matrix, "issue2_voting.csv",
row.names = FALSE,
fileEncoding = "UTF-8")
cat("投票数据已保存到: issue2_voting.csv\n")
cat("包含", nrow(vote_matrix), "位投票者的完整排名\n")
# 显示前几行
head(vote_matrix, 5)
```
---
## 综合分析总结
```{r}
#| label: summary
#| echo: false
cat("========================================\n")
cat(" Issue #2 投票分析总结\n")
cat("========================================\n\n")
cat("【数据概况】\n")
cat("- 总投票人数:", length(unique(vote_data$user)), "\n")
cat("- 有效排名记录:", nrow(vote_data), "\n")
cat("- 涉及模型数:", length(unique(vote_data$model)), "\n\n")
cat("【最受欢迎模型】(按总票数)\n")
top3_votes <- head(total_votes, 3)
for (i in 1:nrow(top3_votes)) {
cat(sprintf("%d. %s (%d 票)\n", i, top3_votes$model[i], top3_votes$total_votes[i]))
}
cat("\n【综合评价最佳】(按平均排名)\n")
top3_rank <- head(avg_rank, 3)
for (i in 1:nrow(top3_rank)) {
cat(sprintf("%d. %s (平均排名 %.2f)\n",
i, top3_rank$model[i], top3_rank$avg_position[i]))
}
cat("\n========================================\n")
```
---
## 教学要点总结
### 1. 排序数据的分析方法
| 分析目标 | 推荐方法 | 注意事项 |
|----------|----------|----------|
| 总体偏好 | 平均排名 | 样本量要足够大 |
| 头部表现 | 第一名次数 | 反映"最受欢迎"程度 |
| 分布特征 | 热力图/箱线图 | 展示排名的离散程度 |
| 两两比较 | 配对检验 | 需要更复杂的统计方法 |
### 2. tidyr 数据转换技巧
```r
# 长格式 → 宽格式(展示用)
data %>%
pivot_wider(
names_from = rank,
values_from = model,
names_prefix = "Rank_"
)
# 宽格式 → 长格式(分析用)
data %>%
pivot_longer(
cols = starts_with("Rank"),
names_to = "rank",
values_to = "model"
)
```
### 3. 可视化选择指南
| 场景 | 推荐图表 | 原因 |
|------|----------|------|
| 展示总量 | 条形图 | 直观比较数值大小 |
| 展示分布 | 箱线图 | 显示中位数、离散程度 |
| 展示矩阵 | 热力图 | 二维数据的颜色编码 |
| 展示趋势 | 折线图 | 显示随时间变化 |
### 4. 排序数据的统计注意事项
1. **不要直接使用参数检验**:排序数据不满足正态分布假设
2. **考虑使用非参数检验**:如 Mann-Whitney U 检验、Kruskal-Wallis 检验
3. **注意样本量**:小众模型的排名可能受样本量影响
4. **考虑策略性投票**:人们可能不显示真实的弱偏好
---
## 扩展思考
1. **如何处理缺失排名?**
- 有些投票者可能没有排满5个模型
- 可以使用加权方法或对缺失值进行插补
2. **如何计算加权排名?**
- 第一名得5分,第二名得4分... 这样计算总分
- 或使用指数权重(第一名得 2^4 分,第二名得 2^3 分...)
3. **如何进行统计显著性检验?**
- 使用 Friedman 检验比较多个相关样本
- 使用 Nemenyi 检验进行事后比较
4. **如何可视化投票者偏好的一致性?**
- 使用聚类分析识别投票者群体
- 绘制偏好网络图
---
*本案例展示了排序数据的完整分析流程,从数据采集到多维度可视化,体现了数据科学中处理复杂数据结构的核心技能。*