---
title: "Issue #1 - 学生加入申请数据分析"
subtitle: "从 GitHub Issue 到结构化数据的完整流程"
format:
html:
toc: true
toc-depth: 3
code-fold: show
code-summary: "显示/隐藏代码"
code-tools: true
editor: visual
execute:
warning: false
message: false
---
## 案例概述
本案例展示如何**从非结构化的 GitHub Issue 评论中提取结构化数据**,完整演示数据科学工作流程中的数据获取、清洗、验证、分析和可视化环节。
### 学习目标
完成本案例学习后,您将能够:
1. **使用 GitHub API 获取数据**:理解 RESTful API 的基本概念,掌握 `gh` 包的使用方法
2. **解析非结构化文本**:使用正则表达式从自由文本中提取结构化信息
3. **建立数据验证机制**:设计数据质量检查规则,识别异常数据
4. **进行描述性分析**:使用 `dplyr` 进行数据汇总和统计
5. **创建数据可视化**:使用 `ggplot2` 生成专业的统计图表
6. **生成可复现报告**:使用 Quarto 整合分析流程并发布
### 数据结构
| 字段 | 类型 | 说明 | 示例 |
|------|------|------|------|
| `student_id` | character | 学号(13位数字) | "2025303110116" |
| `name` | character | 姓名(2-4个中文字符) | "张三" |
| `interest` | character | 感兴趣的研究方向 | "农业遥感" |
| `created_at` | POSIXct | 评论创建时间 | "2024-01-15 08:30:00" |
### 数据来源
数据来自 [GitHub Issue #1](https://github.com/D2RS-2026spring/members/issues/1),学生在 Issue 中以评论形式提交个人信息,格式如下:
```markdown
学号:2025303110116
姓名:张三
感兴趣的方向:农业遥感
```
---
## 数据获取:连接 GitHub API
### GitHub API 简介
GitHub 提供了功能完善的 REST API,允许程序化的方式访问平台上的几乎所有数据。对于本项目,我们需要获取特定 Issue 下的所有评论。
**API 端点结构:**
```
GET /repos/{owner}/{repo}/issues/{issue_number}/comments
```
其中:
- `{owner}`: 仓库所有者(本例为 `D2RS-2026spring`)
- `{repo}`: 仓库名称(本例为 `members`)
- `{issue_number}`: Issue 编号(本例为 `1`)
### 为什么选择 `gh` 包?
R 社区提供了多种访问 GitHub API 的方式:
| 方式 | 优点 | 缺点 |
|------|------|------|
| `httr` + 手动构建请求 | 灵活,完全控制 | 需要处理 URL 编码、分页等细节 |
| `gh` 包 | 简洁,自动处理分页,智能认证 | 功能封装后灵活性略降 |
| `gh` CLI + `system()` | 利用现有认证 | 依赖外部工具 |
本项目主要使用 `gh` 包,因为它:
1. **自动处理分页**:当评论数超过 100 条时,自动获取所有页面
2. **智能认证**:自动检测 `GITHUB_PAT` 环境变量
3. **R 友好的输出**:直接返回 R 列表结构
### 数据获取代码
```{r}
#| label: setup
#| include: false
# 加载必要的 R 包
library(httr) # HTTP 请求(备用方案)
library(jsonlite) # JSON 数据解析
library(dplyr) # 数据操作
library(stringr) # 字符串处理
library(ggplot2) # 数据可视化
library(tidyr) # 数据整理
library(showtext) # 中文字体支持
# 配置中文字体(macOS 系统路径)
# 注意:不同操作系统字体路径可能不同
# Linux: "/usr/share/fonts/truetype/wqy/wqy-microhei.ttc"
# Windows: "C:/Windows/Fonts/simhei.ttf"
if (file.exists("/System/Library/Fonts/wqy-microhei.ttc")) {
font_add("WenQuanYi", "/System/Library/Fonts/wqy-microhei.ttc")
} else if (file.exists("/usr/share/fonts/truetype/wqy/wqy-microhei.ttc")) {
font_add("WenQuanYi", "/usr/share/fonts/truetype/wqy/wqy-microhei.ttc")
}
showtext_auto()
```
```{r}
#| label: data-acquisition
# 使用 gh CLI 获取数据(避免 API 限流)
# 先检查本地是否有缓存数据,避免重复调用 API
cache_file <- "issue1_comments.json"
if (!file.exists(cache_file)) {
# 获取 Issue 1 评论数据
# --paginate 参数会自动处理分页,获取所有评论
system("gh api repos/D2RS-2026spring/members/issues/1/comments --paginate > issue1_comments.json")
message("已从 GitHub API 获取数据并缓存")
} else {
message("使用本地缓存数据")
}
# 读取本地缓存数据
# simplifyVector = TRUE 会将 JSON 数组转换为 R 向量
all_comments <- fromJSON(cache_file, simplifyVector = TRUE)
# 显示数据概览
cat("获取到", nrow(all_comments), "条评论\n")
cat("数据包含以下列:", paste(colnames(all_comments), collapse = ", "), "\n")
```
### 理解 API 返回的数据结构
让我们查看一条原始评论的结构:
```{r}
#| label: inspect-structure
# 查看第一条评论的结构
comment_example <- all_comments[1, ]
cat("评论 ID:", comment_example$id, "\n")
cat("用户名:", comment_example$user$login, "\n")
cat("创建时间:", comment_example$created_at, "\n")
cat("评论内容(前200字符):\n")
cat(substr(comment_example$body, 1, 200), "...\n")
```
**JSON 结构解析:**
GitHub API 返回的评论对象包含以下关键字段:
| 字段 | 类型 | 说明 |
|------|------|------|
| `id` | integer | 评论的唯一标识符 |
| `node_id` | string | GraphQL 节点 ID |
| `html_url` | string | 评论的网页链接 |
| `issue_url` | string | 所属 Issue 的 API 链接 |
| `user` | object | 包含评论者信息(login, id, avatar_url 等) |
| `body` | string | 评论的 Markdown 内容 |
| `created_at` | string | 创建时间(ISO 8601 格式) |
| `updated_at` | string | 最后更新时间 |
---
## 数据解析:从文本到结构化数据
### 解析策略
学生在 Issue 中的回复格式各异,我们需要设计灵活的解析策略:
**可能的格式变体:**
```markdown
# 格式 1:标准格式
学号:2025303110116
姓名:张三
感兴趣的方向:农业遥感
# 格式 2:简化格式
2025303110116
张三
农业遥感
# 格式 3:包含额外信息
大家好!
学号: 2025303110116
姓名: 张三
方向: 农业遥感
请多关照!
# 格式 4:分隔符变体
学号:2025303110116
姓名: 李四(注意冒号不同)
```
### 正则表达式解析
```{r}
#| label: data-parsing
#' 解析学生信息
#'
#' 从 GitHub Issue 评论正文中提取学号、姓名和感兴趣方向
#'
#' @param body 评论正文文本
#' @return 包含 student_id, name, interest 的数据框
parse_student_data <- function(body) {
# 处理 NA 或空值
if (is.na(body) || body == "") {
return(data.frame(
student_id = NA_character_,
name = NA_character_,
interest = NA_character_,
stringsAsFactors = FALSE
))
}
# 提取学号 - 匹配各种格式
student_id <- NA_character_
# 格式1: "学号:2025303110116" 或 "学号: 2025303110116"
# (?<=...) 是正向后行断言,匹配前面是特定模式的位置
# [\u4e00-\u9fa5] 是中文字符范围
if (str_detect(body, "学号[\uff1a:][\\s]*(\\d{10,13})")) {
student_id <- str_extract(body, "学号[\uff1a:][\\s]*(\\d{10,13})") %>%
str_extract("\\d{10,13}")
}
# 格式2: 直接以数字开头的行
else if (str_detect(body, "^(\\d{10,13})")) {
student_id <- str_extract(body, "^(\\d{10,13})")
}
# 提取姓名 - 匹配 "姓名:张三" 或 "姓名: 张三"
name <- NA_character_
if (str_detect(body, "姓名[\uff1a:][\\s]*([\\u4e00-\\u9fa5]{2,4})")) {
name <- str_extract(body, "姓名[\uff1a:][\\s]*([\\u4e00-\\u9fa5]{2,4})") %>%
str_replace("姓名[\uff1a:][\\s]*", "")
}
# 提取感兴趣方向
interest <- NA_character_
# 匹配 "感兴趣[的方向方向]*:xxx"
interest_pattern <- "感兴趣[的方向方向]*[\uff1a:][\\s]*([\\u4e00-\\u9fa5a-zA-Z0-9]+)"
if (str_detect(body, interest_pattern)) {
interest <- str_extract(body, interest_pattern) %>%
str_replace("感兴趣[的方向方向]*[\uff1a:][\\s]*", "") %>%
str_trim()
}
# 清理兴趣字段中的常见无效值
if (!is.na(interest) && interest %in% c("无", "NA", "暂无", "没有", "")) {
interest <- NA_character_
}
data.frame(
student_id = student_id,
name = name,
interest = interest,
stringsAsFactors = FALSE
)
}
# 测试解析函数
test_cases <- c(
"学号:2025303110116\n姓名:张三\n感兴趣的方向:农业遥感",
"2025303110116\n李四\n环境科学",
"学号:2025303110116 姓名:王五"
)
for (test in test_cases) {
cat("\n测试文本:\n", test, "\n")
cat("解析结果:\n")
print(parse_student_data(test))
}
```
### 批量解析所有评论
```{r}
#| label: batch-parsing
# 将数据框转换为列表以便遍历
# split() 函数按行分割数据框
comments_list <- split(all_comments, seq(nrow(all_comments)))
# 使用 lapply 批量解析每条评论
# 结果是一个列表,每个元素是一个数据框
student_data_list <- lapply(comments_list, function(x) {
parse_student_data(x$body)
})
# 使用 bind_rows 将所有数据框合并为一个
student_data <- bind_rows(student_data_list)
# 添加原始数据中的其他字段
student_data <- student_data %>%
mutate(
user_login = all_comments$user$login,
created_at = all_comments$created_at,
html_url = all_comments$html_url
)
# 数据质量概览
cat("解析结果概览:\n")
cat("总评论数:", nrow(all_comments), "\n")
cat("成功解析学号:", sum(!is.na(student_data$student_id)), "\n")
cat("成功解析姓名:", sum(!is.na(student_data$name)), "\n")
cat("成功解析兴趣方向:", sum(!is.na(student_data$interest)), "\n")
```
---
## 数据验证:确保数据质量
### 验证规则设计
数据验证是数据分析中至关重要的一步。我们需要定义明确的规则来检查数据的完整性和正确性。
**学号验证规则:**
1. **格式规则**:必须以 `2025` 开头(华农 2025 级学生)
2. **长度规则**:必须是 13 位数字
3. **字符规则**:只能包含数字,不能有字母或符号
**验证的重要性:**
- **数据完整性**:确保后续分析基于正确的数据
- **异常检测**:识别可能的输入错误或恶意数据
- **反馈机制**:帮助数据提供者纠正错误
### 实现数据验证
```{r}
#| label: data-validation
# 添加验证字段
student_data <- student_data %>%
mutate(
# 去除首尾空白
student_id = str_trim(student_id),
# 验证学号格式:2025开头 + 9位数字 = 13位
valid_id = str_detect(student_id, "^2025\\d{9}$"),
# 记录验证失败原因(用于调试和反馈)
validation_note = case_when(
is.na(student_id) ~ "学号缺失",
!str_detect(student_id, "^\\d+$") ~ "包含非数字字符",
nchar(student_id) != 13 ~ paste0("长度错误(", nchar(student_id), "位,应为13位)"),
!str_detect(student_id, "^2025") ~ "非2025开头",
TRUE ~ NA_character_
)
)
# 统计验证结果
cat("=== 数据验证报告 ===\n")
cat("总记录数:", nrow(student_data), "\n")
cat("验证通过:", sum(student_data$valid_id, na.rm = TRUE), "\n")
cat("验证失败:", sum(!student_data$valid_id | is.na(student_data$valid_id), na.rm = TRUE), "\n")
```
### 不合规数据展示
```{r}
#| label: invalid-data
# 筛选不合规记录
invalid_data <- student_data %>%
filter(!valid_id | is.na(valid_id)) %>%
select(student_id, name, validation_note, user_login, created_at) %>%
arrange(created_at)
if (nrow(invalid_data) > 0) {
cat("不合规数据明细:\n")
knitr::kable(invalid_data,
caption = "学号验证失败记录",
col.names = c("学号", "姓名", "失败原因", "GitHub账号", "提交时间"))
} else {
cat("✅ 所有学号均通过验证!\n")
}
```
---
## 数据保存:导出结构化数据
### CSV 导出
将清洗后的数据保存为 CSV 格式,便于后续使用:
```{r}
#| label: data-export
# 准备导出数据 - 只包含有效学号
export_data <- student_data %>%
filter(valid_id) %>%
select(
学号 = student_id,
姓名 = name,
感兴趣方向 = interest
)
# 保存为 CSV
# row.names = FALSE: 不添加行号列
# fileEncoding = "UTF-8": 确保中文正确编码
write.csv(export_data, "issue1_students.csv",
row.names = FALSE,
fileEncoding = "UTF-8")
cat("数据已保存到: issue1_students.csv\n")
cat("共", nrow(export_data), "条有效记录\n")
# 显示前10条记录作为预览
head(export_data, 10)
```
---
## 数据分析:描述性统计
### 1. 学号前缀分析
学号的前几位通常编码了年份和专业信息。让我们分析学生的分布:
```{r}
#| label: prefix-analysis
#| fig-height: 5
# 提取学号前缀(前4位)
prefix_analysis <- student_data %>%
filter(valid_id) %>%
mutate(
prefix = substr(student_id, 1, 4),
# 尝试解读前缀含义
prefix_label = case_when(
prefix == "2025" ~ "2025级",
TRUE ~ prefix
)
)
# 统计前缀分布
prefix_count <- prefix_analysis %>%
count(prefix, sort = TRUE) %>%
head(10)
# 可视化
ggplot(prefix_count, aes(x = reorder(prefix, n), y = n)) +
geom_bar(stat = "identity", fill = "steelblue", alpha = 0.8) +
geom_text(aes(label = n), hjust = -0.3, size = 3) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
labs(
title = "学号年份/专业前缀分布",
subtitle = "基于有效的学生记录",
x = "学号前缀",
y = "学生人数"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi")
)
```
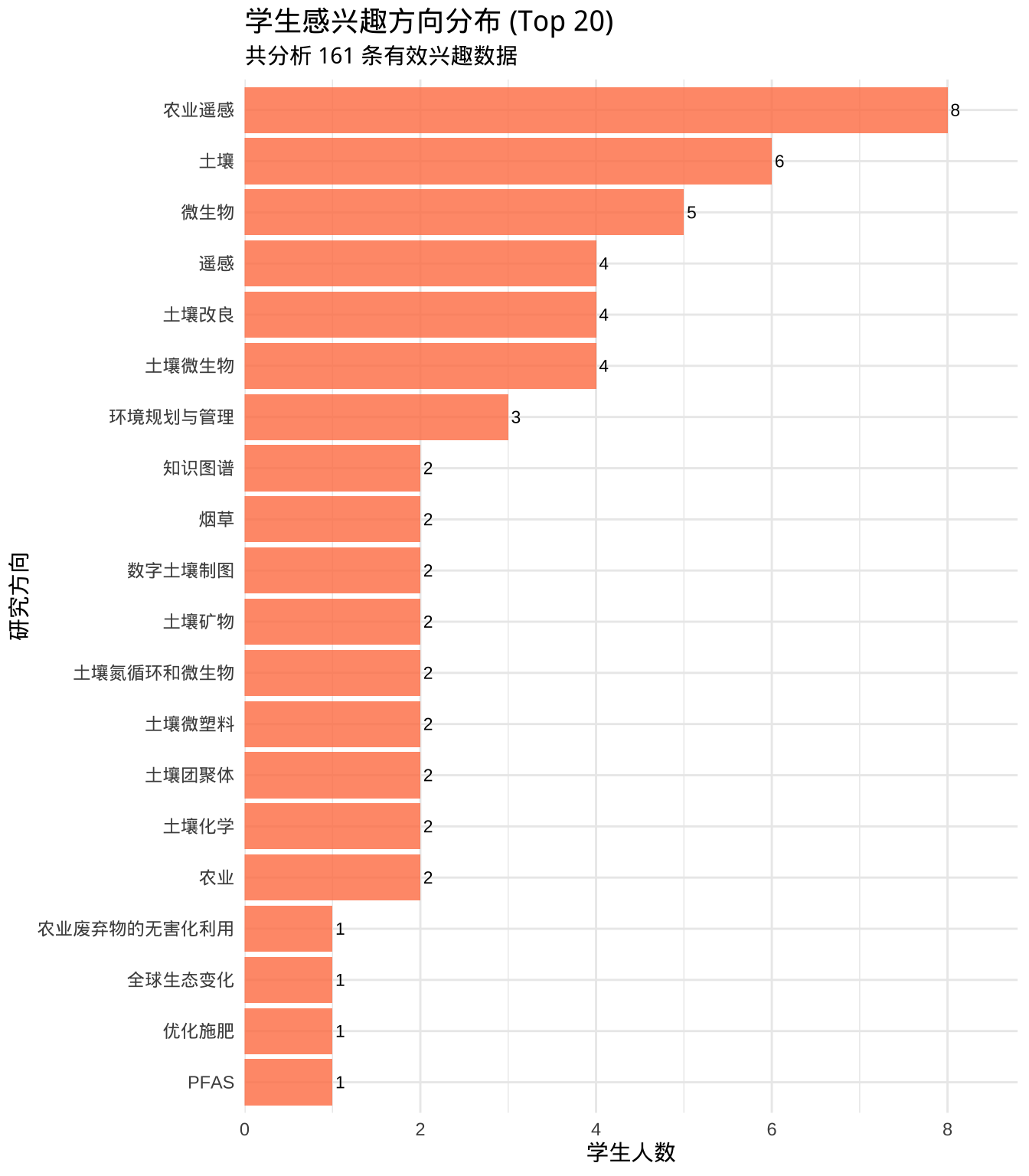
### 2. 感兴趣方向分析
分析学生的研究兴趣分布:
```{r}
#| label: interest-analysis
#| fig-height: 8
# 清洗和统计感兴趣方向
interest_analysis <- student_data %>%
filter(valid_id, !is.na(interest)) %>%
mutate(
# 标准化方向名称(处理大小写、空格等)
interest_clean = interest %>%
str_trim() %>%
str_to_lower() %>%
str_replace_all("[[:space:]]+", " ")
)
# 统计方向频次
interest_count <- interest_analysis %>%
count(interest, sort = TRUE) %>%
head(20)
# 可视化
ggplot(interest_count, aes(x = reorder(interest, n), y = n)) +
geom_bar(stat = "identity", fill = "coral", alpha = 0.8) +
geom_text(aes(label = n), hjust = -0.3, size = 3) +
coord_flip() +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
labs(
title = "学生感兴趣方向分布 (Top 20)",
subtitle = paste0("共分析 ", nrow(interest_analysis), " 条有效兴趣数据"),
x = "研究方向",
y = "学生人数"
) +
theme_minimal() +
theme(
plot.title = element_text(size = 14, face = "bold"),
text = element_text(family = "WenQuanYi")
)
```
### 3. 数据完整性分析
```{r}
#| label: completeness-analysis
# 计算各项数据的完整率
completeness <- student_data %>%
filter(valid_id) %>%
summarise(
总记录数 = n(),
有学号 = sum(!is.na(student_id)),
有姓名 = sum(!is.na(name)),
有兴趣方向 = sum(!is.na(interest)),
全部完整 = sum(!is.na(student_id) & !is.na(name) & !is.na(interest))
) %>%
mutate(
学号完整率 = round(有学号 / 总记录数 * 100, 1),
姓名完整率 = round(有姓名 / 总记录数 * 100, 1),
兴趣完整率 = round(有兴趣方向 / 总记录数 * 100, 1),
全部完整率 = round(全部完整 / 总记录数 * 100, 1)
)
knitr::kable(completeness, caption = "数据完整性统计")
```
---
## 完整数据质量报告
```{r}
#| label: final-report
#| echo: false
# 生成综合报告
cat("========================================\n")
cat(" Issue #1 数据质量报告\n")
cat("========================================\n\n")
cat("【数据获取】\n")
cat("- 总评论数:", nrow(all_comments), "\n")
cat("- 数据获取时间:", format(Sys.time(), "%Y-%m-%d %H:%M:%S"), "\n\n")
cat("【数据解析】\n")
cat("- 成功解析学号:", sum(!is.na(student_data$student_id)), "\n")
cat("- 成功解析姓名:", sum(!is.na(student_data$name)), "\n")
cat("- 成功解析兴趣:", sum(!is.na(student_data$interest)), "\n\n")
cat("【数据验证】\n")
cat("- 有效学号:", sum(student_data$valid_id, na.rm = TRUE), "\n")
cat("- 无效学号:", sum(!student_data$valid_id, na.rm = TRUE), "\n")
cat("- 验证通过率:", round(sum(student_data$valid_id, na.rm = TRUE) / nrow(student_data) * 100, 1), "%\n\n")
cat("【导出数据】\n")
cat("- 有效记录已保存至: issue1_students.csv\n")
cat("========================================\n")
```
---
## 教学要点总结
### 1. API 数据获取的最佳实践
- **缓存策略**:将 API 响应缓存到本地文件,避免重复请求
- **错误处理**:检查响应状态码,优雅处理网络错误
- **分页处理**:使用 `--paginate` 或 `.limit = Inf` 获取完整数据
### 2. 正则表达式的应用技巧
- **多模式匹配**:为常见的格式变体准备多个正则表达式
- **非贪婪匹配**:使用 `*?` 和 `+?` 进行最小匹配
- **后行断言**:使用 `(?<=...)` 提取特定位置之后的内容
### 3. 数据验证的重要性
- **前置验证**:在分析开始前检查数据质量
- **规则明确**:验证规则应该清晰、可测试
- **反馈机制**:向数据提供者提供清晰的错误信息
### 4. dplyr 管道操作的工作流
```r
data %>%
filter(条件) %>% # 筛选有效数据
mutate(新列 = 计算) %>% # 添加派生列
group_by(分组变量) %>% # 设置分组
summarise(汇总统计) %>% # 计算汇总值
arrange(排序变量) # 排序结果
```
### 5. ggplot2 的可视化原则
- **数据映射**:明确将数据变量映射到视觉属性
- **图层叠加**:使用 `+` 连接多个图层
- **主题定制**:使用 `theme_*()` 和 `theme()` 调整外观
---
## 扩展思考
1. **如何处理更复杂的文本格式?**
- 考虑使用专门的解析包如 `readr::read_delim()` 处理表格格式文本
- 对于非结构化文本,可以探索 NLP 技术
2. **如何自动化数据验证?**
- 使用 `assertr` 包进行管道式数据验证
- 设置持续集成(CI)自动检查数据质量
3. **如何处理数据更新?**
- 使用时间戳跟踪数据变化
- 实现增量更新机制,只处理新评论
4. **如何保护学生隐私?**
- 学号脱敏处理(如本例中的中间位替换)
- 控制数据访问权限
- 遵守数据保护法规(如 GDPR)
---
*本案例分析展示了从原始数据到结构化输出的完整流程,体现了数据科学工作中数据获取、清洗、验证、分析和可视化的核心技能。*